
아무 생각없이 들어간 영상이었는데 모두연에서 실시간으로 세미나가 발표중이었다. 2시간을 몰입해서 본 강의에서는 정지훈 교수님이 나와 이론관련 내용보다 사람 그리고 조직 중심의 세상, 그리고 통찰력을 말씀해주셨다.
- 영상/사진 출처: StableDiffusion과 ChatGPT의 기술에 대한 이해와 비즈니스 인사이트 I 모두의연구소 모두팝
- 기사출처: chatGPT & Stable Diffusion 거대한 변화의 시작
영상, 그림, 글 모두 모두연 영상과 교수님 자료를 참고해서 작성했습니다. 박사님의 워딩을 타이핑 한 것으로 출처나 저작권에 문제가 있다면 언제든 연락주세요. 수정하겠습니다.

 사진출처 : 모두연
사진출처 : 모두연
정지훈 교수님은 한양대 의대에서 부터 출발해 IT AI 등 다양한 분야를 거친 인사이트로 테크펀드 파트너에, DGIST 겸임교수에, 모두연 CVO 까지 이분의 인사이트를 들으며 발표하신 내용을 작성한다.
chatGPT & Stable Diffusion 거대한 변화의 시작
- Jihoon jeong MD, MPH., phD
- General Partner / K2G Tech Fund
- CVO/ModuLabs
chatGPT 보다 개인적으로 Stable Diffusion을 훨씬 더 중요하게 생각한다. 역사에 대한 이야기 하겠다. 아깝고 안타까운 것들이 많다. 지나고 나니 아쉽다. 비지니스는 앞으로 아무도 모른다. 별여별 것들이 다 나올 것이기 때문에. 엔젤투자 160개 넘게 하고, 한국에서 미국가는 k2g tech fund도 실리콘벨리에 있어서 투자도 많이 하는데, 시드 투자 결국 사람들이 한다. 결국 사람들의 이야기, 조직의 이야기, 그들이 어떻게 만들어서 어떻게 성장했나가 중요하다. 여기서는 사람, 조직에 대한 이야기를 하겠다.
ChatGPT
 사진출처 : sbs 뉴스기사
사진출처 : sbs 뉴스기사
2016년부터 알파고 어떻게 되었나 시작해보겠다. 원래 제프리 힌튼의 슈퍼비전팀 부터 시작해야하고 그래야 알렉스 크리잡스키 나오고, 그리고 디엔엔 리서치 하면서 오픈ai 나온 연구자 이야기 해야하는데 그건 너무 길어지니까.
2016년 3월, 알파고, 딥마인드 회사 뜬다. 일반인들한테 AI 알려지는 계기.
2013년말 영국에서 출발했는데 딥마인드를 보고 구글이 딥러닝 될거 같으니까 투자. 강화학습 명가.
2015년말 openai에 아이디어 가진 사람들이 모이기 시작, 큰 회사들 그러니까 ibm, google, facebook ai reshegrop, 케프리힌튼 구글 얀르쿤 페스트푹, 거대기업들이 모든것을 차지할것 같은 느낌 그래서 모인다.
연구자그룹, 투자자/기업가 그룹, 엔지니어 그룹 총 3그룹으로 공동창업한다. 시작은 Sam Altman(지금 openai 대표, 원래 Y Combinator, 실리콘벨리 Seed accelerator 프로그램 하는 사람, 한번 엑싯하고 파트너로 openai 왔다가 지금은 대표) ai 가 세상을 바꿀것 같은데 이와 관련된 것을 하고 싶지만 풀타임으로 들어올 수 없어서 엘론머스크에게 말을 한다. 엘론 머스크가 돈 만들어서 유명한 사람 왕창 데리고 온다.
투자가/기업가 그룹
Sam Altman - Y Combinator 관계 또는 투자자
Trevor Blackwell - Y Combinator 관계 또는 투자자
Jessica Livingston(리빙스턴) - Y Combinator 관계 또는 투자자
Reid Hoffman(리드호프만) - Linkin 창업자
Elon Musk - 테슬라 창업자
Peter Thiel(피터틸) - 페이팔 공동 창업자, CEO, 페이팔의 리더, 페이펄마피아 수장, 페이스북 투자, 제로투원 책 저자
이 사람들이 돈을 댔고
연구자 그룹
andrej karpathy (openai -> 테슬라 -> 지금 다시 openai)
durk kingma -(구글) 네덜란드, VAE 만든, variational auto encoder, diffusion 기술의 힌트를 가장먼저 제공, 네덜란드 독일 제일 잘했다.
john schulman - 강화학습
ilya sutskever - 치프 사이언티스트 되었고(논문 많이 쓴 사람)
Wojciech Zaremba -
그런데 연구자들이 모이고 돈이 모여서 페이퍼까지는 괜찮았는데 openai도 뭔가를 만들어야하니까 연구해서 페이터만 내는것은 안된다. 뭐가 만드는 사람들이 필요하다. 그래서 엔지니어링 필요하다. 가장 중요한 역할 greg brockman 이 한다.
엔지니어 그룹
Greg Brockman - Stripe 결제솔루션(페이팔만큼 유명, CTO 출신, AI쪽이 아닌, 근데 여러 회사 돌아다니다가 갑자기 AI에 꽂힌, 연구 안해본 사람이 그래서 무작정 쫓아가서 교류시작, 자기가 맡아서 자기가 하겠다)
Vicki Cheung - Stripe 개발했던
Pamela Vagata - 엔지니어
이렇게 출발한다.


- 엘론 머스크 - 돈 대는 사람
- Sam Altman - 지금 ceo
- ilya sutskever - 치프 사이언티스트(논문 많이 쓴)
구글이라든지 여러 회사의 컨트롤 받지 않는 그런 것을 만들고 싶다로 출발. 아까 연구자들. 이 사람들 대다수 강화학습 하는 사람. 강화학습 많이 모여있으니 먼저 만들자. 그떄 유행이 강화학습 제네렐 인텔리전스, 가장 중요할 꺼라는 분위기 믿음 있어서 시작하려고 했으나
그런데 여기 사람들 다 풀타임이 아니었다. 다 파트타임으로 일하던 사람들
- Sam Altman - Y Combinator 대표라 풀타임 아니었고
- ilya sutskever - 아직까지 구글 AI. 다니고 있었고
대다수 회사를 그만두고 나오는 사람이 없었다. 누군가는 장소, 사람 모으고 해야하는데. 그래서 Greg Brockman이 나선다. 구글도 아니고 Stripe도 그만뒀으니 내가 하겠다. 그럼 누구 데리고 오지?
바로 Joshua Benjio(요슈아 벤지오)

왼쪽 - Joshua Benjio(요슈아벤지오) , 오른쪽 - Greg Brockman
인공지능 3대 얘기할 때 제프리힌튼, 얀르쿤, 요슈아벤지오
- 제프리 힌튼 - 구글
- 얀르쿤 - 페이스북
- 요슈아 벤지오 - 무소속, 이 사람만 ms 가끔 어드바이즈만 했지 소속 없었다.
그래서 이해관계 없는 사람으로 갔다. 우리가 이런 것을 하려고 하는데 가장 잘 할 수 있는사람 추천해달라. 요시아밴조 교수가 명단을 준다. 니들이 큰 회사만큼 연봉은 없지만 비전 이런 얘기해봐. 들을 만한 애들 리스트 줄께. 그렇게 아까 위 사람들 쫓아가서 모으게 된 것.
Greg Brockman 아파트에 옹기종기 모여서 시작.

처음에 뭘 만들었냐? openai gym

돌아갈 수 있는 테스트환경. 연구자들 고고하게 논문이나 쓰고 있으니 우리라도 만들자. 해서 이런 것들 만들어서 활용할 수 있게 뿌린다. openai 강화학습 테스트 환경 만들고 뿌리게 된다.
20..년 딥마인드, 스타크래프트 왕창 이기고 2019년 openai, 도타2 세계 챔피언 Rerun 을 이기면서 유명해진다.(Rerun vs OpenAI Five)

이때까지 딥마인드에 대항하는 오픈 되어있는 강화학습 집단으로 시작.
2017년 andrej karpathy 엘론머스크의 꾀임에 테슬라로 넘어간다. 테슬라 오토파일럿, 오토드라이빙 하는, 테슬라 AI 리서치 최고자리에 오른다. 이때부터 엘론머스크랑 openai랑 틈이 벌어진다. 일류를 위해 어쩌구 하면서 만들었는데 뛰어난 엔지니어 하나 데리고 가니까 미묘한 틈 생긴다. 그래서 그 뒤에 openai가 돈 모자르고 할 때 샘 알트만은 투자하던 사람이니 관리경영을 위해 같이 일하는 사람들 스톡옵션도 있어야하고 하니 ms와 딜 하게 되는데 2019년에 엘론머스크와 사이가 나빠진게 아니라 이미 카파시 데려가면서 벌어져 있었다고 함. 그 동안 엘론머스카가 투자한 돈은 기부한것으로 처리하겠다고 퉁쳤다는 인터뷰가 있음.
Attension is All you Need
2017년말 인공지능 판이 확 바뀌게 되는 엄청난 논문 나온다. 원래 논문 제목 이렇게 안지은다. 욕 많이 먹었다. 제목 장사 한다. 구글, Transformer 아키텍쳐 많이 쌓으면 다 되더라 하는 획기적인 논문.
- Ashish Vaswani - 1저자
- Noam Shazeer -
- Niki Parmar -
- Jakob Uszjoreit -
- Llion Jones - 유일하게 현재까지 구글에 남아있는
- Aidan N. Gomez -
- Lukasz Kaiser -
- Illia Polosukhin - 조직장, 갑자기 블록체인에 빠져서 나중에는 나가서 회사 차린다. 니어 프로토콜.
이게 논문을 이해하기 위해 3가지를 알아야한다. 3가지의 목적과 공부하는 철학이 너무 다르다.

Machine Learning
- Supervised 정답이 있는 데이터로 테스크를 줬을때 그 문제를 잘 풀어낼 수 있는 학습방법 문제를 디파인하고, 개, 고양이 문제 풀때, 사진을 주고 개냐 고양이 풀려고 하는 문제 정의되어 있고, 정의되어있는 문제에 답제공하는 데이터가 많으면 인간보다 잘한다!
한계 - 생각보다 데이터 얻기가 쉽지 않다. 모두 다 비용이다. 문제를 정의하지 않으면 답을 풀 수 없다.
-
Reinforcement 데이터 없을때 출발 가능, 승패 명확에 좋아서 게임 이런곳에 쉽게 적응, 그런데 접목해서 할 수 있는 일이 많지 않았다.
-
Unsupervised 데이터 기반이라 데이터만 많으면 특성 뽑아서 그룹핑하는, 우리가 하는 일의 대부분, 뇌가 하는 일의 대부분, 굉장히 많은 데이타를 작은 데이터로 만드는, 다차원의 데이터를 저차원으로 꾸기는, 그렇게 만들어진게 그것에 이름을 붙이거나 네이밍을 할 수 이게 되면 그것을 바탕으로 연결하거나 의미를 지을 수 있게 된다. 그것이 토큰, 심볼화, 벡터로 표현하기도 하고 여러가지 용어로 표현, 숫자 덩어리, 숫자를 줄였다 늘렸다 하는 작업, 예전에는 이것을 하기 위해 넌리니어 많이 했는데 초공간, 복잡한 분포 많이 쓰곤 했는데 GPU가 발전하면서 선형으로 matmul 한게 빠르기 때문에 그걸로 치환해서 사용하기 시작, 그래서 딥러닝이 발전. 그래서 unsupervised로 할 때 가장 중요한게 숫자, 데이터 숫자가 많아지면 할 수 있는게 많아진다. 데이터 양 자체가 많아지면 좋으니까 데이터를 잘 처리하는 곳에 유리해지는, 데이터가 많고 데이터를 잘 처리할 수 있다는 말은 인프라가 빵빵해야 된다는 것, 인프라가 빵빵한 곳이 유리한 싸움이라는 반증
얀 르쿤의 케익 2016년 키노트부터 얀르쿤의 키노트

2016년 알파고,
- cherry - 케익의 저 위에 체리가 강화학습이야. 맛있고 멋져보이지만 퍼센트는 작은
- icing - 바깥의 크림, 이게 supervised
- cake - 케익의 실제 빵이 unsupervised/predictive 이게 인텔리전스의 정수다. 가장 중요한 것은 뭐가 문제인지, 인텔리전스의 핵심이 predictive, 앞으로 뭔 일이 벌어질지. 그걸 하려면 이걸 해야해! 주장한다.
그러다가 2019 IEEE 이때 처음 뜨는데, 유립스 발표할때 처음 봤다. 이때 Self-Supervised Learning 을 들고 나온다.

Self-Supervised Learning 은 supervised와 unsupervised의 중간이다. unsupervised은 답을 주지 않는 것이고 학습할 꺼리가 없으니까 클러스터링해서 모아서 비슷한 것을 찾아내는것으로 학습하기 어려운데, 지도를 하지 않아도 지도가능한 데이터만 줘도 할 수 있는 것들이 많다는 것! 어떻게? 중간을 비우는 것. 선후관계 바꾸는것. 예를 들어 구멍채우기 문제, 괄호넣기 문제, 정답은 텍스트 자체다. 구멍 뚫은 것이 문제고 구멍에 채운것이 답, 데이터 자체가 답, 이게 Self-Supervised Learning. 또 앞 뒤 순서가 바뀐거라면 원문이 정답. 이런 식으로 이런 종류의 충분한 숫자를 많이 넣으면 할 수 있는게 많을 것같다. 앞으로 미래를 예측하거나 바뀌거나 이런 것의 가장 중요한 포인트가 나올 것이다. 라는 시기.
이런 시기에 Alec Radford(알렉 라드포드)라는 사람이 등장.

Alec Radford - 보스턴 올린공대 출신, 단과대학, 학부때 GAN 좋아하고, 기타리스트, 아티스트, 데이비타라는 친구랑 GAN 이미지 트위터 많이 올리던 친구인데 openai로 엔지니어로 학부 마치고 들어감(아직도 20대) 가서 초기에는 환경만드는 코드작업하다가 생성형 AI에 관심을 가지고 공부하고 얀르쿤의 Self-Supervised Learning을 보고 있었는지, 트렌스포머를 굉장히 크게 만들어서 거기에 데이터를 Pre-Training으로 많이 때려놓고 나중에 여러가지 일을 할 수 있도록 하는 Fine-tunning 작업을 하게되면 굉장히 다양한 것을 할 수 있지 않을까?
그게 이 논문
Improving Language Understanding by Generaive Pre-Training
2018년 나온 이 논문이 GPT, 이 논문의 1저자.
또 이후에 다시 설명하겠지만 멀티모달리티, 이미지와 언어를 같이 얶여서 하는 가장 중요한 연구가 Clip 이라는 연구가 2019년 나온다.
Clip: Connecting text and images
2019 년 발표한 이 논문에도 1저자. 제일 뛰어나고 중요한 숨은 공로자.
2019년에 ms 가 이런 것들을 보고 openai에 과감히 투자. gpt1은 약간 그랬는데 gpt2는 재밌는 글들을 만들기 시작하고 2020년에 gpt3 나오니 2019년 gpt2 정도 되는 데모를 보고 투자했을 것이다.

사티아 나델라, 샘 알트만 둘이 손을 잡게 된다. 가장 큰 이유는 빅모델로 갔기 때문에 트레이닝 인프라가 필요한데 ms 에저 클라우드로 돌리면 돈이 너무 많이 들어간다. 그래서 안그래도 연봉도, 비영리로 출발해서 버티기 힘드니 ms 에서 과감히 투자, 인프라 제공하니 손을 잡게된다.
이제 chatGPT
chatGPT = GPT-3.5 + Reinforcement Learning from Human Feedback (RLHF)
gpt3.5와 강화학습 중에서도 휴먼 피드백이 들어간 버전 2개를 합친 것이다. 아까 Self-Supervised Learning 은 unsupervised와 supervised의 중간 언저리 였고 이게 GPT라면 이건 여기에 강화학습이 들어갔는데 인간의 선택까지 끼어들어간. 굉장히 짬뽕된 복합기술이다.
GPT3는 pre-training 해서 175B 175억개 파라미터를 가지고 큰 데이터를 넣고 학습. 굉장히 많은 데이터를 넣고 학습한 데이터모델을 가지고 있으면 거기다 대화를 가르치면 chatGPT고 번역을 가르치면 번역GPT.
큐샷트레이닝, transfer learning 적게 하고도 트렌스레이션 하는 이런 것들을 잘한다는 것을 찾아낸다.
큰 회사들이 이것을 보고 따로따로 목적을 가지고 하지 말고 커다란 모델로 big model(이때는 big model, 지금은 foundation model) 만들어서 각각 fine tuning 하면 되겠네?

그래서 큰 기업들, 클라우드에 큰 투자를 하기 시작
강화학습.

고양이에게 보상을 주면서 잘 움직이게 만드는. 강화학습은 진짜 여러가지를 잘 하는데 리워드를 잘 만들어야한다. 리워드를 잘못 만들면 이상한 일들이 일어난다. reward engineering.
보트경주에서 출발점과 도착점이 있는데 reward를 잘 못주면 이렇게 출발점에서 시작해 바로 돌아서 끝점을 반복하는 방법으로 트랙을 돌게 된다. 이게 제일 빠르다. 그렇지만 반칙이다. 그런데 규칙에 그런게 있냐? 라고 물어보면 .. 이러면 안되지! 인간이 보기에 이상한. 이런 일들이 일어나기 떄문에
골엔 리썰라이먼트 ai의 위협, 윤리, 나중에 나올게 이것.
그래서 이런 것들을 잡기 위해 인간의 피드백 집어넣자하는 딥마인드와 openai가 했던,
deep reinforcement learning from human preferences

deep reinforcement learning from human preferences 이 논문이 RLHF 이다. 아까 chatGPT에 들어가는.

예를들어 강화학습으로 play하는 선택지를 주고 사람이 관전하다가 이거 같아. 말할 수 없어. 같이 객관식이 들어가면 인간이 보기에 그럴싸한 것들을 한다.

덤블링 하는 것을 학습. 사람처럼 머리와 다리처럼 만든 gym 환경에서 학습하는 것을 보고 사람이 고른다 human feedback.

그래서 이것을 GPT에 chat 에 넣은게 chatGPT.

사람이 만들어낸 답들을 가지고 학습을 하고 파인튜닝. 대화형이니까 달 착륙한 것을 설명해봐 라고 하는 대화형 내용들을 가지고 학습해놓고
그것을 강화학습으로 나오는 출력물 중에 라벨러가 선택하게 하고, 그 리워드 모델을 가지고 나중에 다시 학습하게 되는데 이 작업은 초반에만 해주지 나중에는 라벨러가 필요가 없어진다.

그랬더니 이상한 짓을 덜 하더라. 사람들이 보기 그럴싸한 답변을 하더라. 그래서 한번 써볼까?
이렇게 나온게 openai 의 chatGPT가 과감하게 나온거다. 그런데 이 모든 것이 transformer 에서 시작.

transformer 는 구글에서 만든것. 원천기술 가지고 있고 연구도 많이했고 그런데 문제는 혼자 남았다.
Llion Jones - 유일하게 현재까지 구글에 남아있는
Ashish Vaswani, Niki Parmar - Adept 독자적 GPT 모델 만드는, ACT1 모델 만들고 스타트업, 투자 많이 받은
- Niki Parmar - Adept 독자적 GPT 모델 만드는. ACT-1
- Noam Shazeer - 에즈워드 만든, 엔지니어, character.ai 회사 리드 호프만 투자.
- Jakob Uszjoreit - Inceptive 바이오 AI 회사
- Aidan N. Gomez - Co:here 회사, 구글이 많이 투자.
- Lukasz Kaiser - openai
- Illia Polosukhin - NEAR incorporated 니어 프로토콜, 블록체인회사
어뎁트는 Adept ACT-1, Transformer for actions, gpt 같은 다음 버전 제공하는 그런 회사. 펀딩 받고 하고 있는.

코히어, 구글 docs 인테그래이션 되어진. ms office에 chatgpt 붙이니 마니 이건 구글.

구글 내부에서는 뭘했냐? 람다 작년 이미 만들어서 발표 google io 에서. 그런데 구글은 Kodak과 같은 위치. 검색 잡아 먹힐 수 있고 큰 회사라 욕도 먹을 수 있고, 그래서 이상한 것을 섣부르게 발표 안되는 위치, 내부 테스트 잘 되고 있는 상황에서 엔지니어 의식이 있는 것 같아요. 뉴스 세고 또 얘를 짤라서 난리가 난. 그래서 경영진 입장에서 내부 스트레스 많은 상황, 그래서 인프라나 만들고 있자. 인프라 먼저 구축하고 있으면서 그것의 라지모델 만들고 있쟈. 그런데 일 커진. openai가 ms 손을 잡고 chatGPT 가 나온. 그래서 구글도 안 따라가면 안되는 상황 후발주자되어버리는. 준비된게 많은, 어쨌거나 빨리 할 수 있는 직접만든, 테스트 끝난 람다 서비스 모델을 바꿈. 그게 Bard. 경량화 모델. 파리에서 멋찌게 발표했지만 뭐가 틀려서 하루 주가 8% 빠지는.

character.ai
Noam Shazeer가 링크드인 창업자한테 투자받은 22hundred mil, 케릭터 음성, 행동, NPC 형태 게임 AI 같은 철저한 엔터, 게임 제공하는 인간의 말과 행동. 형태. transformer 만든 사람이 나와서 한 회사.

구글에서 진짜 밀고 있는 것. 바로 이것. pathways language model (PaLM)
pathways 는 구글의 딥러닝 인프라. 하드웨어 인프라. TPU v4. 단일 모델로 여러가지를 할 수 있도록하는. 단지 언어모델이 아닌. 오늘 발표한 PaLM E 는 빅모델 단어모델 뿐만 아니라 이미지, 비전 트렌스포머, 로봇센서까지 들어가게 했다. 그래서 여러가지 동시에 처리할 수 있는 제네럴 인프라를 하드웨어 서비스로 하는. 페쓰웨이 시스템. 여기에 들어있는라지 랭기지 모델.이라 생각하면 되고 이게 TPUv4를 가지고 가속한다.
밀리언 오브 테스크를 이 써버 인프라에서 이걸로 다 할 수 있는 느낌. 그렇게 준비를 하는것. 대규모 서비스를 해야하니까.
https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html

8 billion 에서 커지면 커지니까 할 수 있는게 많아. 540 billion paramters
그래서 아직 게임은 끝나지 않았다. 지켜봐야 한다는 의미.
Anthropic

아모디 남매. RLHF 논문에도 나온 openai 주요 리서치 중에 한 사람. 아직 서비스가 완벽하지 않은데 거기다 ms 과 딜, ms 같은 회사에 돈 받아서 하는게 무슨. 결국 둘이 뛰쳐나와서 Anthropic
훨씬 신뢰성 있고 해석 가능하고 인간이 다르기 편한, 엉뚱한 답 덜하는 초점으로 만들게 되는. 그게 클라우데 서비스. 최근 조금씩 보이기 시작하는데 구글이 여기에 지난달에 3000억 투자. Anthropic 의 클라우데를 람다 바드 하면서 클라우데를 2번 타자처럼 지키는것 같음.
조금 더 체개화된 느낌

헌법. constitutional

인간과 가깝게 원칙 뽑아내는. 리비전, 크리틱도 하고 revision, critique 우리 사회를 따르는 중요한 것들을 뽑고 그걸 따르게 하는. 그래서 헌법. 그래서 세이브티, 릴라이어빌리티, 이런 아이디어로 하는 클라우데.
그리고 딥마인드.

딥마인드 그동안 놀았냐? 강화학습 하면서 시작이 늦었다. 2021년 Gopher(고퍼)로 스타트.
- GPT2 2019
- GPT3 2020
이니까 많이 늦은. Gohper 는 280B 모델로 스타트, chinchilla 70B, Flamingo 80B, Gato 1.2B, Sparrow 70B 딥마인드 동물 농장. 이게 딥마인드의 베이스 모델.
GPT3 가 170B 니까 1700억 개의 파라메터가 있는 것인데 비해 구글은 70B 반이 안되는 700억 파라메터로 더 작은데 성능이 더 좋고 토큰 수가 더 많고.
플라밍고는 언어 + 영상 가토는 많이 줄였는데 로보틱스에 쓰려고. 근데 이게 이번에 발표한게 540개로 늘림 친친라를 기반으로 서비스를 내고 있다. 그 중하나가 스페로우 이게 chatGPT 드라마톤 긴 글 장문
친칠라가 더 좋다. 더 작은데도 좋다.
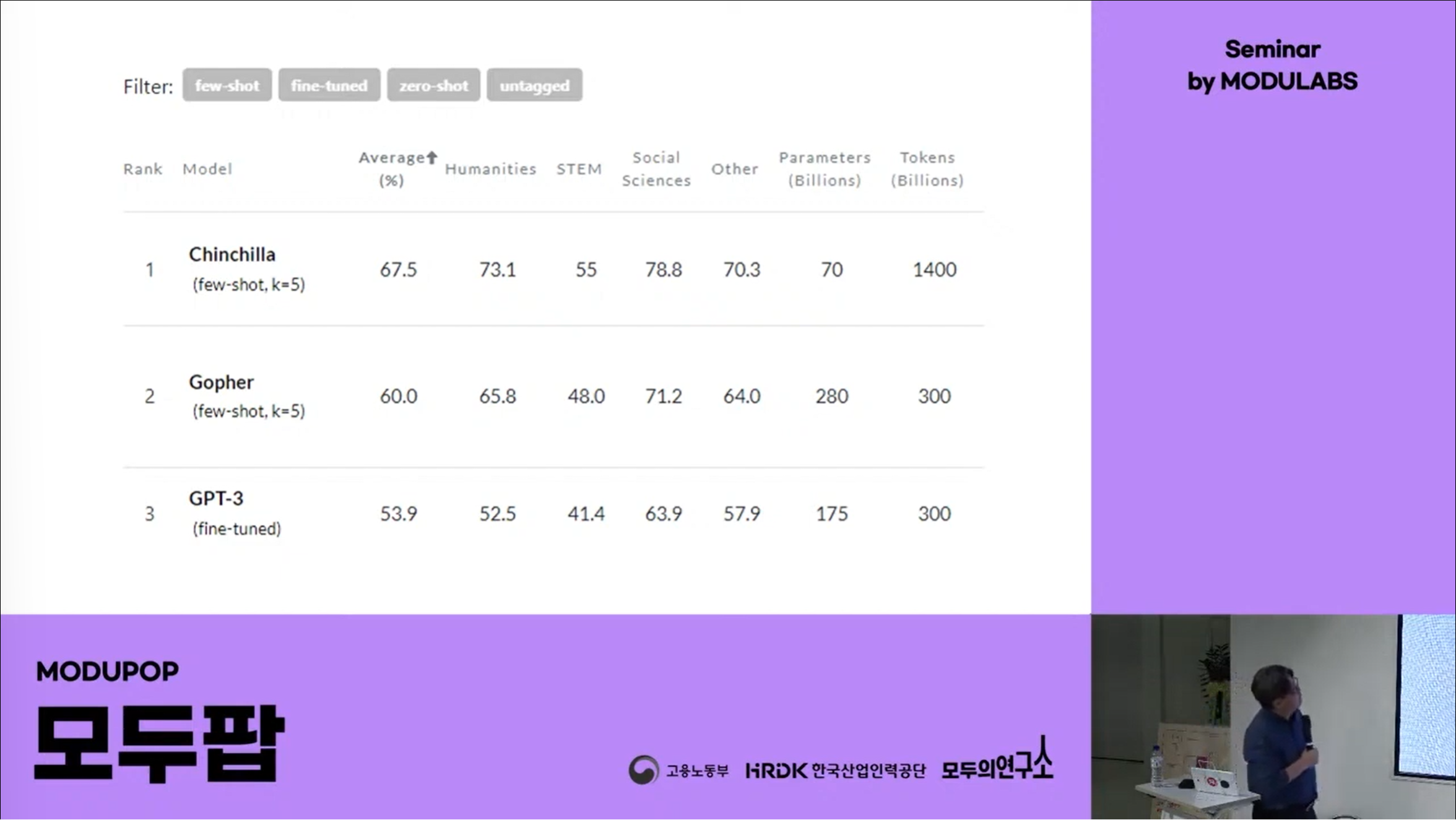
스페로우 대화형, 클라우대랑 비슷. 이상한 짓 제외하는것들 많이 넣어놓음. 조금 더 안전한 릴라이어블. preference 많이 넣어놓은. 지금도 chatGPT 이상한 대답, 언라이어블 문제. 이와 관련된 업그레이드 일어나면서 이 방향으로 진행될 것이다.

얀르쿤

그러면 얀르쿤은 놀았냐? chatGPT 나오고 twitter에 이렇게 떠들었다가 욕을 엄청 먹었다. 융단폭격. chatGPT 는 nothing revolutionary 하다 사람들한테 그렇게 느껴질지는몰라도 별거 아니다. 해서 욕 엄청 먹었다. 페이스북가서 그동안 시간이 지났는데 만들어놓은 것도 없으면서 뭐라하냐.
그런데 지금보면 2019년 생각했던 Self-Supervised Learning 방향으로 얀르쿤이 생각했던 방향으로 갔었던 것이다.
그런데 왜 이렇게 얘기했나 했더니 밑밥 깔아놓은 발표였던 것이다. 그게 LLama 라마. open source project.

2월 24일 발표

재밌는게 7B 모델부터 65B 모델까지 한건데 이게 늘어나면 training 부터 인퍼런스 에 들어가는 컴퓨테이셔널 파워가 2배 3배로 늘어나느게 아니라 기하급수 훨씬 많이 늘어난다. 늘어나느 써야하는 전기. 그래서 작은게 좋은건데 gpt3가 175B 인데 13B 짜리가 GPT3와 비슷하게 나와. 65B는 제일 유명한것 대비 작은데 PaLM, Chinchilla 수치와 비슷하게 나오는데 사이즈는 훨씬 작은. 그래서 65B도 잘나간다는 모델보다 좋고 13B 작은 모델은 GPT3과 비슷해.
그리고 이건 open-source로 한다. 그리고 GPL v3 라이센스로 마음대로 쓸 수 있어. 프랑스팀. fair-Paris 파리에서 한것 같음. 다국어가 많음.

이렇게 할 수 밖에 없었던 이유는 페이스북은 아마존, 구글 ms 처럼 클라우드 인프라를 제공하지 않는다. 그래서 그 싸움으로 가면 안된다. 그래서 오픈소스로 던져버렸더니 사단이 나기 시작.
자기들이 이긴다기 보다 이 판 자체를 뒤집어 엎게다는 이야기. 생태계를 바꾸게다는 의미.
오픈소스로 풀어놓으니까 세상에 특이한 엔지니어가 많다. 희안한 엔지니어가 퀀타이제이션 경량화 해서 만들어서 깃헙에 다 뿌린다. 누구나 다운받고 할 수 있는 상황
LLaMa: int8 edition

int8 정수니까 성능 떨어지겠지만 rtx3090에서 돌아간다. 좋은 pc에서 돌아갈 수 있게 만들었다.
그렇게 되면 재밌어진다. 춘추전국시대, 무기를 다 푼것과 마찬가지. 이렇게 안된거라면 인프라 많고 돈 많고 클라우드 많이 가지고 있는 곳이 이기는데, 상황이 묘해짐. 역습.
아마존 Amazon
아마존 소리소문없이 준비한게 많다.

AlexaTM 20B 모델 이게 다국어를 정말 잘한다. 이건 transformer 를 쌓은게 아니라 Sequence-to-sequence learning (Seq2Seq), 양방향, 이건 translation, 번역, 써머라이즈가 굉장히 뛰어남.

Ultra-large 모델을 제공할 수 있는 굉장히 많은 인프라 자체 개발해서 AI 칩 4종 개발. EC2 UltraCluster
- 그래피톤. 기본
- 인퍼런시아- 인퍼런스 전용 칩
- 트레이니움 - 트레이닝 전용 칩

온디멘드 access로 여러 기업들하고 협력해서 서비스 할 것 같다. 아마존은 웃긴게 스타과학자도 없고 논문 발표도 책자도 많이 안내는데 신기한게 시간이 지나 보면 SageMaker 쓰고 있고 소리소문 없는. 아마존 생각보다 엄청 잘 할지도 모른다.
지금 다들 구글 ms 싸움으로보고 있는데 , Meta(Facebook)도 다 같이 망해보자고 돌 던진 것도 있고 아마존도 이것들이 있어서 잘 모르겠다. 조금더 지켜봐야겠다.
아마도 생태계를 누가 더 잘 만들어서 편을 만들까. 많은 사람들이 들어와서 쉽게 하는 표준 많이 만들었다. Markup, Dialogue 마크업 랭기지로. 이런 도구들 아마존이 잘한다. 클라우드 인프라에 올려서 쉽게.
Richard Socher

그리고 리차드 소처 스텐퍼드 페이페일 교수님 대학원생 똑똑한 친구. 세일즈포스닷컴 창업자. 그 사람이 얘한테 투자해서 아인슈타인랩, 세일즈포스 내에 AI 랩 만들어서 여러가지 만들게 했는데 새로운 포탈 만들래요. 2019년 독립하겠다 했더니 쿨하게 회사 투자금 잔뜩 주는. 그게 you.com
Chris Manning 및 Andrew Ng와 함께 딥 러닝에 대해 연구하면서 박사 학위를 취득했으며 최고의 Stanford CS PhD 논문 상 수상
you.com 은 chatGPT, code 쓰는, 문서 그런걸 포탈처럼 묶어놓은 메이져와 다르지만 볼만한 회사.
Naver도 삼성전자와 뭔가를 하고 있다.
여기까지가 ChatGPT 이야기
Stable Diffusion
Generative AI 의 시작은 생각보다 엄청 빠르다. 2가지가 핵심이었다.

- Auto-Encoding Variational Bayes, 2012년
- Generative Adversarvial Nets, 2013년
Diederik kingma, 구글에 있다가 Openai 연구자그룹으로 온 암스트롱 대학교 대학원생일때 VAE (variational auto encoder)를 발표한다. 2012년. Max Welling 교수는 나이가 많은. kingma 는 구글 브레인에 와서 인턴 하다가 openai 공동창업, diffusion 기술의 힌트를 가장 먼저 제공, 네덜란드 독일 제일 잘했다.
Ian Goodfellow 구글 브레인, 애플 ai 총책임, GAN 논문 발표 2013년.
생각보다 많이 오래된, 알파고 보다 더 오래된. 그래서 그 뒤에 이미지 퀄리티가 별로고 Mode Collapse 라고 해서 이상한거 그려지는, 학습시키다 보면 어느 순간 제대로 학습이 되지 않을 때도 많고. 아직까지 높은 수준까지 오기 전까지는 관심없고 재밌기는 한데 이걸 뭐 얼마나 제대로? 이 정도가 VAE, GAN 가지고 있었던 한계
GAN 은 위조와 위조구별과 둘을 경쟁시켜서 결론은 위조한걸 진짜처럼 만들어서 진짜구별 못하게 하는, 적대적 경쟁, 좋은 점은 edge 있는 날카로운 것들은 잘 만들어 내는데 특정 케릭터리스틱이 과대평가 되는 경우가 많다. 고양이 귀가 특징을 잘못 잡아서 귀가 이따만한 봐줄 수 없는. Mode Collapse.
VAE는 안정적으로 확률적으로 뿌리면서 줄였다가 늘리는것. 줄이면서 컨디션, 이게 뭐다라는 표상 만들어졌으면 그걸 반대로 확산, 컨디션 주고 뿌리면서 만드는 것이라 좋은 점은 Mode Collapse가 없이 이상한게 안나온다. 괴물이 안나온다. 나쁜점은 정보가 없는 것에서 하려다보니 희뿌연게 나온다. edge가 안나오고, 고해상도 이미지를 jpeg로 만든 느낌. 이게 줄였다 늘렸기 때문에.
그래서 두개를 합치기도 하고 해보면서 기간이 많이 흐르게 된다.
제일 먼저 희안하게 무너지긴 하지만 아티스트 입장에서 추상화도 있으니 이걸 이용하면 재밌는게 나오겠네 해서
Mario Klingemann 마리오 클링게만

Deep dream 만들고 아트 영상 미디어 아트로 쓰고. 있다가

2017년 NIPS (NeurIPS 로 이름 바뀌기 전) 롱비치에서 제 1회 creativity 워크샵

Machine Learning for creativity and desine, 워크샵이 열린다. 지금부터 얘기하는 Stable Diffusion 하는 사람들이 여기서 나오기 시작한다.
Gene Kogan, 2018년 짐 코간
Interactive Telecommunications Program (ITP / IMA)
GAN 가지고 뉴욕대학교에서 과정을 하나 개설. NYU ITP 과정, NYU ITP 는 미션 레슨, HCIS 관련된 블록형 코딩, 교육혁신 많이 이뤄낸 석사 프로그램. 거기에 the Neural aesthetic 프로그램 개설. 이건 가을의 실라버스.

그때 모두연에서는 양재 AI 허브 모두연 할 때 학생 모집해서 creativity AI 해서 팀 많이 만들고 프로젝트도 하고, 2019년 12월 뉴립스 creativity 워크샵 2회. 거기 papar 2개가 억셉 되었다.

RUNWAY
크리스토발 발렌수엘라
RUNWAY ML 제논.
AI magic tools 포토샵 같이 만든. 창업자가 발렌수엘라.
칠레에서 학교다니던, 아티스트, CS 컴퓨터 사이언스 하던 사람이 아니고, NYU ITP 프로그램 석사 하면서 the Neural aesthetic 하면서, creativity 워크샵 와서 공부도 하고 그러다가 자기가 아티스트기도 하고 아티스트가 쓸 수 있는 도구를 만들어야겠다, 이것저것 연결해서 만든건, 프론트엔드, 씌우고 그거로 석사학위 논문 발표했는데, 아티스트 들이 와서 쓸만하니 사업하면 안되니, 그래서 공동창업하자, 대학원 다니던 친구 2명 더 해서 같이 창업. 2018년
지금 보면 굉장해보이지만 그때 2018 2019년 쓸때는 이상한거 많이 나왔다. GAN 을 썼기 때문에. 장난감 같은데 이게 엄청난 도구가 될까? 생각했는데 또 스타가 등장.

GAN 하고 VAE 가 각각 약점이 있었다. Diffusion Stable Diffusion 의 핵심도 Diffusion인데, Diffusion은 UNet 을 사용한다. VAE와 비슷하다. 줄였다가 늘리는, 이렇게 생긴 것은 주로 denoising 잡티제거. 인데 그걸 여러 스탭으로 해서 컨디션 주고 뿌려서 생성해봤더니
마르코브체인 프로세서 이렇게 해서 50단계 해봤더니 어마무시 하게 잘 나온다. 이것에 중요한 것은저기까지 갈 때까지 어떤 숫자. 누군가가 가이던스 가이드를 해줘야하는데 이런 것들을 프롬프트 prompt 형태의 글, 문장으로 하면 좋을거 같아서 그것에 맞춰가는 과정, 그게 Diffusion, 이렇게 했더니 퀄리티가 엄청 났다.
이게 Stable Diffusion 의 핵심

- image information creator 가 있고
- image decoder : 아까 VAE 이미지 뿌려내는 것과 같고
- Text encoder : 앞에 인코딩 파트를 CLIP 모델을 쓴다. (Alec Radford가 2019년에 발표한, Clip: Connecting text and images) openai 의 이미지와 문장 결합하는 네트워크, 그걸 쓰고 Diffusion 했더니 글만 쓰면 나오네, 서비스가 잘 나오네
중요한 것은 이게 어떻게 탄생하게 됐는지 중요하다. 이걸 우리도 할 수 있었는데 하는 아쉬움이 많다. 이게 참 중요하다.

그런데 openai가 오픈을 하지 않고 데모만 하고 Multi modality
openai가 CLIP을 만들고 발표를 하지 않고 2021년 1월에 DALL-E 를 발표한다. CLIP, 자연어처리 에 이미지 넣어서 만든 서비스인데 처음에 이렇게 아보카도 많이 만들어서 논문 냈다. 아보카도 스타일로 만든 의자 만들어봐. 이렇게 나온다. 이미지와 글씨, text, 이런게 멀티모달리티.
그런데 openai가 오픈을 하지 않고 데모만 하고. 신청하면 조금 하게 하는, 이런 것을 하니까. openai 가 openai 맞냐? open 왜 안하냐. 그래서 커뮤니티가 움직인다.

- Eleuther ai (일레터, 엄청난 역할 하게 된다.)
- Laion
디스코드에 openai가 저렇게 하는 짓을 진짜 우리가 오픈해서 하는 커뮤니티를 만들자. 이런 이름으로 하는 커뮤니티, 개발자, 디자이너 모여서 커뮤니케이션, 크게 팀 2개 나뒨다.
- 자연어 팀, GPT 작은 버전 트레이닝도 해보고 큰것도 돌려보고
- Ryan Murdock(아티스트) and Katherine Crowson(엔지니어) 팀
Ryan Murdock, Katherine Crowson 이 둘이서 DALL-E를 보고 발표도 안헸는데 앞에 text 는 GPT 기반으로 붙이고 그 당시는 GAN이였는데 VQGAN 을 붙여서 만들면, 소스코드, 코랩 만들어서 올리면 사람들이 쓰지 않을까? 그게 Eleuther ai
Laion 은 독일 쪽 많다. Large-scale artificial intelligence open network 의 약자. 100% non-profit. 수많은 Naion들이 웹 크롤러를 이용해서 컴포지션을 보니까 핀터리스트 플릭커 블로그 이런 곳의 이미지, 글들을 셋 페어 가지고 사람의 글과 그림을 매칭시키는 셋트를 만든다. 큰 세트, 하이 데피니션 세트, 워터마크 세트, 레벨별로 구분해서 많은 수의 데이터를 모은다. 이걸 모으는 작업을 라이온이 하기 시작.
이 사람들은 검색해도 찾을 수 없다. Katherine Crowson 개발자인데도 문서 만드는 것도 싫어함. 나서기를 싫어하는 샤이한 개발자들. 코랩에 colab 에 올려서 코딩해서 올릴 수 있게 했는데.. 보다 못한 사람이 구글독 google doc을 열어서 대신 써줬다.

이것은 VQGAN과 CLIP 을 가지고 Katherine Crowson이 만든 튜토리얼이야. 너는 이것을 코딩 몰라도 돼. 그냥 쓸 수 있어. 나는 잘 몰라. 만든사람 아니야. 나는 퍼블릭을 원할 뿐이야. 하면서 3,4 페이지 이미지도 없이 작성. 그렇게 시작한다.
이렇게 Stable Diffusion 이 시작하게 된다.

그러다 Emad Mostaque 다톤, https://stability.ai/ 요르단 출신 돈 많은 분 1983년생, 방글라데시 다카 자라다, 영국으로 건너가 옥스포드에서 수학하고 컴퓨터 사이언스 전공하고 영국의 해지펀드 메니저 되어서 돈을 많이 벌었다. 느낌이 피터 티엘의 영국판 같은 사람. 피터 티엘은 엄청난 시장주의자. zero to one 책의 저자의 피터 티엘은 강자가 약자를 억압해도 된다는 사람, 트럼프 쪽 지지자, 굉장한 우파 지지자. 이게 피터 티엘의 사고방식 철학.
이 사람은 헤지펀드 메니저 하면서 돈도 많이 벌고 그뒤에 법인도 많이 만들고
펍어티, 가난한 사람 지원하는, 기부만 하는게 아니라 그걸 돌아가는 시스템 만드는. 이런것에 투자 굉장히 많이 만들고 이런것 하는 사람. 투자도 하고 만들기도 하고 기술이 이런 여러가지 변동시킬 것이라는 것을 알고 있다가 디스코드 들어갔다가 이 팀들을 봄 Laion.
근데 Laion 을 하면 높은 수준의 뭔가가 나올거 같은데 그때 비용 산정을 해보니 A100 Nvidia 그래픽 카드로 200대로 몇시간 계산해보면 60만 달라. 한번 트레이닝 할때 들어갈 것 같더라. 이 친구들이 8억원이 어딨어? 트레이닝 학습을 못하니, 결국 클라우드 리소스가 있어야하는데. 그래서 이 사람이 돈 지원할께. 8억원 가지고는 모자를테니 100억 대줄께. 다른 사람 모으기도 하고. 그렇게 투자해서 학습해서 공개한게 Stable Diffusion. 이렇게 시작된 것이다.

Decentralized grassroots collective of volunteer researchers, engineers, and developers focusing on AI alignment, scaling, and open source AI research.
grassroots 풀뿌리. developers, engineers 들이 돕는. 모두의 연구소다. 이게.
이게 Stable Diffusion 지난 몇 년 간의 이야기이다. 이제 법인 3월. 회사 가치가 조 단위 돌파, 법인이 안 만들어졌는데 조단위 돌파, 투자를 1000억원 넘게 여러군데에서 들어올것 같다.
Emad 가 지원하는 연구자가 많다. 장학생들 처럼 7~8명 더 되는데 자연어 하는 사람도 있고 여러사람 많다. 그런것들 더 할 것이다. LLaMa 같은 것도 발표할 것이다. 적은 자원으로 누구나 쓸 수 있는 것들을 open-source 로 계속해서 발표할 것이다. 그래서 big company 들의 경쟁으로 흘러가지 않을 수 도 있다.
hardward and computer
시작도 크는거
하드웨어 쪽도 시장이 이렇게 크는것이고 chatGPT 도 서비스하면 비용으로 계산해봐야하는데 1개 답하는데 100원하는 서비스하고 1원하는 서비스하고 누가 이길것인가? 결국 나중에 퀄리티는 비슷할텐데. 결국 마지막 가면 비용 적게 쓰는 곳이 이길 가능성이 높아지니 그런 부분들을 최적화해서 제공할 수 있는 하드웨어 인프라가 어마무시해진다.
TPU v4

이것 4대가 pathway를 돌리고 있다. 더 커질 것이다. 이런 것으로 최적화 하면 가격 떨어질 테니 범용은 nvidia 장비를 더 쓸테니 그치만 앞으로 더 두고볼 것이다.
특히 아마존은 Graviton 2017년 부터 만들어서 리비전 4번째 버전까지 쓰고 있다.

- Nitro System
- Trainium
- Inferentia
이런 것들을 돌려서 Ultra cluster 제공하는게 아마존.
이제 삼성전자 네이버 하이닉스도 가능성이 있다고 하는 이유가 뭐냐면. 기존의 시스템 반도체와 다르게 기억용량 들고 있어야하는 양이 많다. 프로세서와 기억한 것과 속도 왔다갔다 빠르게 해줘야하는데 메모리 집적도 중요하고 폰 노이만의 병목이라고 하는데 왔다갔다 버스의 양을 크게해서 IO 빠르게 해야한다. 이걸 멜라녹스가 가지고 있던 기술인데 nvidia가 사서 RTX에 왕창 넣은. 그렇게 하면 메모리 성능 좋아야한다.

HBM, GDDR, On-chip 에도 캐쉬 넣어야하니. 이렇게 시스템 메모리인데 메모리가 어마무시하게 많이 넣어야한다 또 적절하게 활용하는 소프트웨어도 만들어야하고 그래서 네이버 같이 서비스회사와 삼성전자가 잡으면 달라질 것이다. 앞으로 이제 막 시작하려고 하는거라서 두고봐야한다. 뭐든. 플렛폼 쪽은 이런식으로 흘러갈 것이다.
Platform and standards
플렛폼에서 아마존은 웹서비스 클라우드를 지배하고 있다. 2002년 가장 먼저 개념적인 test POC 처음 나오고, 그다음에 아마존이 웹 에저 서비스, 인터넷 에져 os 같은, 인터넷 자체를 운영체제 스택처럼 쓰겠다. 2006 아마존 web seervices stack.

- 밑에 스토리지에 해당하는 S3가 있고
- Elastic compute Cloud EC2
그러니까 결국 컴퓨팅 인프라, 스토리지 인프라, 그리고 메시지큐 세개를 인프라를 놓고 서치 솔루션, 이커머스 위에 프론트엔드를 스택으로 쌓아서 서비스를 하겠다 고 발표하고 적자를 무지하게 냈고 제프베조스가 미쳤다고, 말도 안된다고 생각을 했고

이게 언제까지 바보짓으로?
2006년 시작해서 적자하다가.. 돈 벌기시작한게 2012, 13.. 10년을 버텨서 세계 최고가 되어버린. 그래서 아마존이 1등 하게된.
그 뒤에는

우리나라는 Cloud 하면 아마존 에져?, 한국에서는 네이버 KT? 그런데 지금 보는 이 수많은 회사들이 유니콘,나스닥 상장, 인프라는 깔려있고 데브옵스, 이벤트스트리밍, 런타임, 쿠버네틱스, 시큐리티, 모두 다 빌리언달라 나스닥 상장사들 이런 큰 변화 일어날때. 보기에는 그냥 큰 회사. 그런데 이런 회사들이 성장하고 만들어져서 전 세계 컴퓨팅 인프라, 서비스를 만들고 공급하고 있다. 그럼 AI도 어떻게 될 것인가?
AI는
굉장히 많은 것들에 대응이 되고 접목이 될 것이다.
copilot 하고 chatGPT 시대에 human programmer 들은 뭘 해야할까?

그냥 카피코드하고 물어보고 돌아가나 해보고 안돌아가면 또 물어보고, 그렇게 돌아기길 바라면 되지 않을까? 어쨌든 프로그래머가 일을 하긴 하네? 그렇지만 Dammit.
이런 식으로 사람들이 많이 사용하게 될 것이다.

이제는 어떤 싸움? 결국 Foundation model 하나가 서비스가 됐을때 굉장히 다양한 서비스가 등장을 해서 커질 수 밖에 없고, 그럼 결국 편 많이 먹는 곳이 이긴다. 나랑 같이 하는 회사가 많고 연합군 많이 하는 곳이 가장 쎌 수 밖에 없다. 그래서 Ecosystem war 생태계 구축, 커뮤니티 빌드업이 중요.
네이버도 Foundation model 하이퍼클로바 발표하면서 어뎁테이션 지원도 하고 지원도 받고 몇 백개를 지원하겠다 openai도 최근 샘 알트만 엑셀레이터 출신이니까 펀드조성하고 있어서 펀드가지고 도와주고 하는것 많이 나오고 넘어갈 것 같다.
벌써 짧은 시간 사이에 이중에 얼마나 많은 회사들이 그렇게 큰 회사가 될지 모르겠지만. 등장 이렇게 많이 하고 있다. 서비스 중심 회사들. 이중에 떨어질 곳 떨어지고 성공할 곳 성공하고, 그래서 일부 대기업이 다먹는 그런 일은 없다. 물론 걔네들, nvidia 돈 많이 벌 기회는 있지만 수 많은 기회, 가치 있을 것이다.
이건 구글이 발표한 것. 라지 랭귀지 모델에다가 LLM 이렇게 하라고 했더니 이것과 두개 결합했더니 의미 파악해서 로봇 할 때 알아들을 수 있는 일종의 코드, 수행 코드, 이 말해서 만들어서 움직이게 하는, 이런 시뮬레이션 결과
자연어 레퍼가 위에 생긴것.
모바일 시대에 검색이 사라진 것이 아닌, 모바일 인터페이스가 깔린. 그것처럼 자연처 포함해서 AI가 사람들하고 중간에 끼어서 인터페이스, 중계, 위에 많은 것들이 자동화가 되는,

이 그림은 결국 사람들은 결국 다 들여다보고 있고, 책 릭고 그림 그리는 것은 로봇, 그런데 알고 봤더니 AI가 리플레이스 한게 아니고 이용 잘 하는 사람, 오더 내리는 사람들이 리플레이스 하더라.
이제 시작인 것 같다. Stable Diffusion 경우 비슷한 시기에 시작해서 비슷한 시기에 학회 나가서 비슷한 시기에 발표하곤 했는데 쟤네들은 영어로 디스코드 글로벌 커뮤니티 빌드업해서 이것저것 하면서 실제 만들고 하니 영국에 있는 펀드메니저가 지원도 하고, 그런데 우리는 한국에 갇혀있고. 발표도 하고 교육도 같이 하고 했는데 엑팅에서 acting 에서 만들거나 이런 사람들이 적었던 것. 열심히 공부해서 회사가서 열심히 회사일만 했던 것.
우리도 저런 친구들이 많았으면 우리도 커뮤니티 같은 것을 build 할 수 있지 않았을까 하는 아쉬움.. LLM 은 그렇다 치고, 있는것 가지고 엮어서 만들었으면 했는데.
QnA
미드전이는 어떤 모델 베이스인가?
미드전이도 별로 다르진 않다. 앞에 클립을 썼는지는 모르겠으나 자연어를 통해 프롬프트가지고 생성하는 것은 뒷단은 다 Diffusion 쓰고 있다고 생각하면 되고.
그런데 openai가 어제인가 그제 발표한게 컨시스턴시.
Diffusion의 문제가 뭐냐면 이터레이션 많아서 연산량 많다. 하드웨어 사용량 많다. 그걸 많이 줄여주는데 퀄리티 비슷하게 나오는 것을 발표한 것다. 어쨌거나 디퓨전 개열에 그리는 것은 그것으로, 앞단에는 이미지가 그려내야하는 숫자, 사실 숫자하고 숫자 맵핑해야해놓은 것인데 자연어가 만들어야하는 벡터 임베딩 이 숫자를 커플로 묶어 놓은 것. 이것을 앞단에 쓰는것. 입력은 자연어에서 거기서 뽑아놓은 이미지에다가 컨트롤랩 같은 것은 벡터 위치 그것을 일종의 또하나의 억실러리로 줬다고 생각하면 된다. 원리는 다 똑같다. 스테이블 디퓨진은 모든게 오픈소스 데이터도 풀려있고.
미드전이 달리는 구글과 openai 걔네들이 자기네가 센트럴라이즈 되어 있는 클라우드 서비스로 하는 모델. 그 차이. 기본은 똑같다. 그리고 학습 데이터도 다를 것이다. 데이터가 다르니 다른 결과가 나오지만 결국 똑같다고 생각하면 된다.
character.ai 폭동사태 일어났다. 유저들끼리 회사랑 대립을 세우는 일이 일어났다. 1월 19일이 운영진 실수로 NSFW 필터가 꺼지는 일이 발생했다. 필터가 꺼지니까 character.ai 답변 속도가 엄청나게 빨라졌고 지능이 수직상승하는 결과가 나타났는데 필터가 켜 있을 때는 설정도 까먹을 수 있고 대화 기억도 잘 못하고 어눌한 대화를 한다는지 그런 것들을 유저가 본 입장에서 이게 말이 안된다. 검열 때문에 AI 기능 약화를 하냐. 그래서 19금 유저들, character.ai 사용하고 만들어내는 크리에이터들이 분노하는 사건 있었다. 그래서 책임있는 AI가 화두다. 성능을 원하는 유저가 있고 메이저 기업 올라가는 것들도 있을텐데 그 사이에서 어떤 절충안이 있을지 그런 것들이 궁금하다.
블록체인 이런 쪽에서도 똑같이 하는 얘긴데 우리 사회에는 언제나 규칙이란 것이 있고 세이프티 일라이어빌리티 되게 굉장한 이슈. 풀어달라는 이슈와 그렇지 않은 사람들의 대립은 있을 수 있다. 다만. openai와 google의 사례를 보면 투자도 많이 받고 제도권의 여러가지를 해야하는 기업은 어쩔 수 없이 그런 부분들에 민감하게 대응할 수 밖에 없다. 그에 비해서 도전자 적으로 두려워하지 않는 경우는 이런 것들을 할 수 있다. 단순한게 답을 할 수 있는게 분노한 사람들이 그게 싫으면 자기들이 만들면 된다. 그리고 비즈니스, 돈 많이 투자 받아서 하는 입장에서는, 사실 클라우데 같은 법률, 법 같은 서비스들도 오버헤드 하는 것이다. 인터프리터블 AI 는 오버헤드를 집어 넣는 것이다. 성능이나 유저빌리티 보다 그걸 초점으로 방점으로 만든것이기 때문에. 그게 아니면 떠나면 된다. 시장이 그걸 해결하면 된다.
그래서 character.ai 어려움을 겪고 있다고 한다.
그럴 수 있다. 내부적으로 판단 할 것이다. 직접 서비스 보다는 간접서비스로 돌려서 하는게 좋은 방안이지 않을까? 기업들한테로.
AI 역사 들려주셨는데 AI 자체 모델을 만드는 것도 중요하지만 활용해서 2차 3차 서비스 만드는게 활성화 되어 할 것이다. 라고 말씀하는것 같다. 그게 MLOps 같은 것인지, 내가 공부하려고 할 떄 AI에 대해 공부하는게 미래가능성이 있을지 AIOps를 공부하는게 좋을지 궁금한다.
AIOps MLOps DevOps DataOps 이런 옵피마이제이션은 경영에서 중요하니 당연히 뜰 것이고 그리고 유저빌리티, 디자이너, 사용자 쪽에 리쿼이어먼트를 잘 케치하고 그에 맞는 서비스를 적절하게 만들고 운영하는 파트, 코어를 만드는 종류는 아닌데 개인적으로 이쪽 시장이 더 커질 것이다. 기술자체의 코어를 공급하는 사람 보다는 결과적으로 디자인 쪽이든 제품 프로덕트나 서비스 만드는 사람들, 경제성 이런 것을 확보하는, 새로운 가치창출을 일으키고 결합하는 이런 사람들이 더 많이 필요하다. 개인적으로 AI 대학원, AI 기본 원리 너무 깊이 공부해서 이렇게 하는게 도움이 될까? 하는 회의적인 생각을 한다. 왜냐면 그렇게 필요할 것 같지 않는다. 그것도 필요하긴 한데 너무 과하게 많이 하게 되면 진짜로 필요한 것을 만드는 사람보다, 예를 들어 잘 쓸 수 있는 엔지니어 집단이 더 중요할 수 있다. 너무 원리에 가까운 것을 하는 우려는 있다. 도메인 하고 결합해서 여러가지 시도하고 만들어보는 그런 것이 중요해질것 같다. 결합되어서 바꿀 수 있는 것들이 너무 많다 그런것 하나하나 트라이해보는게 좋지 않을까. 그렇지만 연구하거나 이런 사람들한테도 기회는 있을 것이다. 원래 이런 것이 맞는사람들이 있다. 페이퍼쓰고 연구하고. 그런데 엣날에는 대학에 꼭 갔어야했는데 대학에 안가고도 여러가지 인프라를 활용하거나 이런 것을 해볼 수 있는 인프라가 열려있으니 그걸 좋아하는 사람들은 얼마든지 하면 된다. 어떤 왕도가 있다기 보다. 저 같으면 몇년동안 페이퍼 쓰려고 몇년 쓰진 않겠다. 대신 아카이브 같은 곳에 올리거나 간단한 메모 형태, 블로그, 데이터 올려서 쇼업 하거나 유트브 올리거나 만들어보고 올리고 공유하고 이런게 더 중요한 엑티비티가 아닐까 생각한다.
최근에 Chain-of-Thought 프롬팅 치어틴 많이 보고 이었는데 AI가 대화형태가 되면서 사람들하고 인터렉션 많아지면서 윤리라고 말하는 기준, 커먼센스라고 말하는 것이 되게 흥미롭게 여겨젔는데 그런것에 대한 교수님의 생각이 궁금하다.
그쪽이 재밌는 파트로 연구가 많이 될 것 같다. Chain-of-Thought 를 통해 인간이 생각하는 방식이나 우리가 추론을 하는 것에 대한 특징이나 교육에 형태, 이런 것 까지 고민할 수 있는 부분들이 많이 생겼고, 인간을 인간답게 만드는 theory of mind, TOM, 같은 인지과학에서 얘기하는 것들도 시뮬레이티드 된 것을 통해 많이 해볼 수 있는 상황. 철학도 되게 융성할 가능성도 있다. 데니얼데닛 철학자 Daniel Dennett, 카운트 셀프 피쳐, 가짜자기가 등장 할 수 있는 이론. 가짜자기, 존재의 생각들, 여러가지 풍성해진다. 인간의 뇌 동작, 방식 여기서 힌트 얻어서 연구해서 포인트로 생각기전, 치료 이런 것에 접목할 수 있는 것들이 너무 많다. 저는 그런 식으로 다른 식 접근도 좋을 것 같다. DNA 가지고 단백질 생성 코드, 시퀀스 코드인데 프로틴 코딩하고 있는 것들이 의미없는 코드, 여러가지가 있는데 자연계에 존재하지 않는 프로틴 합성 코드, 이런 것들을 제너러티브 하는 시도도 한다. 완전히 몰랐던 새로운 신약, 단백질 같은 것들 만드는 것도 하고 있고 일종의 언어코드, 할 수 있는 상상의 범위를 넓히면 진짜 해볼만한게 많다. 인문학 쪽에 할게 많다. 옛날 부터 그랬다. 의과대학을 나왔는데 마스터, 석사는 보건정치관리학, 사회과학 계열을 썼다. 그때도 인공지능 썼다. 옛날 그때 2003년 디씨전트리, 어쏘시에이션 룰, 케이스 베이스 추론, 이런거 썼다. 설문 사회과학 답변 어떻게 생각하는지 찾는 방법론, 그 당시 언어가 Noam Chomsky(노암 촘스키)가 얘기한 기호주의 심볼릭, 결국 심볼간에 그래프로 연결되어 있는 것이 우리가 생각하는 어떤 그림으로 생각하는. 석사를 그걸로 했다. 박사는 아까말씀드린 Unsuperived learning, Dimentional 리direction 엄청나게 많은 데이터를 줄이는것, 사실 그게 지금까지 핵심이다. 그거하고 거기에 어떤 것을 설렉션해서 인간한데 디서너블 하게 보여줄 수 있는가. 컬러스페이스 맵핑으로 보여주는 것을 했는데 색깔로 보여주는. 사람이 결국 AI 프로세싱 컴퓨팅이 만들어낸 결과하고 인터렉션하는 방법인데 직관적으로 컬러 디퍼런시에이션을 해주는게 빨리 차이를 찾아낼 수 있는. 그렇게 했는데 학문이란게, 아까 석사는 그걸로 했고 박사는 옵틱스 그건 물리학, 완전히 다 다른거 같지만, 다 그런 것들을 했다. 학문 나눠놓고 이거저거 하라는게 말이 되는가 싶기도 하고 관심 영역 넓히고 자기가 재밌는거 하면 된다. 누가 왜 무엇을 그 당시에 나올 수 밖에 없는 이유 찾고 그런 식으로 상호작용 거시적으로 보면 볼 수 있는게 많다.
금융IT R&D에 근무중인데 chatGPT 가 너무 핫해서 조사해서 보고하려는데, 정작 금융권, 관공서에서는 이런 많은 돈을 들이고 할 수 있는 것은 없네, 적용할 수 있는 것들이 없네. 이런 분위기. 기존에도 AI 관련 모형, 과제가 시도되고 있는데 이런 생성 AI들이 금융, 관공서에 어떻게 스며들지 교수님 의견 듣고 싶다.
관공서는 사람들이 필요로 하는 알아듣게 하는, 민원 쪽에 쓸 수 있게, 틀려도 컨펌정도 하면 되니까 그런데 그게 얼마나 지금하는 서비스 대비 좋아질지 모르겠다.
금융 부분은 솔직히 그냥 그대로 쓰면 큰일나는. 사람들이 원하는 것을 어떤 상품이 됐든 뭐가 됐든 고객들의 의도를 파악해서 주고받고 해서 선택의 도움을 준다든지, 이런 유저인터페이스 쪽에 도움이 될것 가고, 그냥 전자동으로 해서 막하고 그런 것은 조심해야할 것이다. 금융이나 의료도 미션크리티칼 한 것은 클라우데나 이런 것처럼 중간에 안전장치들을 몇개 더 가지고 있어야겠고 경우에 따라서 Circuit Breaker 써킷프레이커 프로토콜 같은 것도 있어야 겠다. 지금도 사실 하이프르컬 쓰레딩(?) 같은 경우에서도 개인적으로 전세계에서 통용되는 Circuit Breaker Protocol이 있어야한다. 안그러면 컬렙스 되기 때문에. 그런 부분들의 안전장치 같은 것들을 만들면서 해나가면 어느정도 해볼만한 것들이 있지 않을까. 그러면 하려는 사람들이 굉장히 공부를 많이 해야된다.
막연한 질문이라 망설였는데 굳이 AI를 나눠보자면 넌심볼릭/심볼릭 AI로 나눠볼 수 있는데 지금은 넌심볼릭 쪽으로 자본 집약적 싸움의 구도가 되었는데, 혹시 심볼릭이냐 아니냐를 떠나서 완전히 새로운 패러다임 나와서 지금의 기존의 비즈니스를 뒤집을 만한 상황이 올 것으로 생각하는지, 아니면 클루가 있는지 정보가 있는지 궁금하다.
완전히 새로운 것이 나올것이라고 생각하지 않는다. 이미 모든 것은 만나고 있다고 생각한다. 원래는 분류를 해서 Supervised/Unsupervised/Reinforcement 나눴는데 다 짬뽕해서 다 쓰고 있다. 지금 워크플로우 같은 것을 만들거나 또는 예를 들어 CLIP 같은 것만 봐도 결국에는 벡터 임베딩 간에 페어링한 것이다. 그럼 심볼 페이링과 다를게 없다. 그럼 심볼릭 철학이 어느정도 들어간 것이다. 이제 더 중요한데 open api 형식으로 이들 간의 플로우로 가게될 텐데 그럼 그래프. 그럼 그건 우리가 흔히 얘기하는 넌심볼릭/심볼릭 구분하는 것 자체가 별 의미가 없는게 아닌가 개인적으로 생각하고 있고 다만 많이 봐야할 것으로 생각하는 것은 인간과 심리학, Max Tegmark 맥스 테그마크, MIT교수 그 팀에서는 원래 Max Tegmark 교수가 물리학 교수인데 AI 에서 많은 것을 한다. 진짜 다학자이다. 생물, 심리학, 법, 철학 전공 컴퓨터사이언스 이런 사람들 뭉쳐서 발달 심리학, 뇌에 바이오 인스파이얼드에다가 딥러닝 써서 이런 저런 실험하는데 그런 식의 다양한 접근 같은 것에서 발전이 나오지 않을까. 완전히 새로운 이멀징 하기 보다는 기존에 있었던 것들이 적절하게 컨피네이션 되면서. 아까 GAN, VAE 보면 완전히 새로웠다기 보다 장단점 모아서. 그 방향으로 갈 것 같다.
영어측면에서는 상당한 성과가 있지만 chatGPT 같은 경우 한글 성능이 너무 미치지 않는다. LLAMA도 한글은 지원하지 않고, chatGPT나 앞으로 Faang 에서 나오게될 LLM을 한국 enterprise 환경에 적용하기 위해서 현재 인프라 위에 어떤 것을 더 고려할 수 있을까요?
한글 집어넣어서 학습하면 되죠. 라마 같은 경우 코드가 오픈되면 저기 들어가는 컨프런스 집어넣어서 fine tunning 만들면 되니까. 이런 것 하는사람 반드시 나올거고 여러기업들 안하면 분명 나올것이고 저기 집어넣는 글타래 만드는 사람들도 있을 것이고, 네이버, 카카오 만드는 것들도 있으니까 저는 그렇게 크게 걱정 안해도 될 것 같다.
자녀들이 인공지능 세상에서 준비해야할 학습법은 무엇이 있을까요? 일반학교의 제도권 교육에서는 아직 인공지능 시대에 대한 교육이나 준비, 커리큘럼이 전혀 없어 보입니다.
인공지능을 연필이나 이런 것을 쓰는 것처럼 잘 활용하는 교육이면 충분할 것 같다. 교육 자체는 달라질게 없다고 생각한다. 인공지능 시대라고 인공지능 학과를 만드는게 옳은가? 그건 잘 모르겠다. 완전히 다른것 다 해봤지만 어차피 다 공부 했다. 얼마든지 보면 다 할 수 있는건데 그것만 전문가 찍어서 하는게 맞나. 되려 인간으로써 꼭 갖춰야하는 교육이 더 중요한것 같다. 개인적으로 윤리나 어떤 것이 예쁘고 아름답고 기쁘고 감동이뭐고 이런 것들, 체육이 뭐고 몸의 어떤, 인간 그 자체, 인간으로 관련된 그런 교육이지 않을까. 수학 같은 것도 수학 자체의 특징과 이게 아름답고 왜 이런 것을 알고 공부했으면 더 재밌었지 않을까. 마치 문제풀이 기계처럼 했으니까 다들 싫어하게 된거지 변별력 이딴 소리 외워서 찍어서 맞처서 하는. 그 자체는 교육 본질에 가깝게 다가가지 않을까, 그런 것을 제대로 제공하지 않는 교육들은 망하지 않을까. 학위보다 자기의 포트폴리오하고 이런것들 잘 하는 사람 중심으로 커뮤니티 빌드업해서 만들고 이렇게 해서 일자리 생길 것이라는것을 알게되면 그런 부분 대응 안한 것을 알게 될것이다. 중요한 것은 학교 제도권 교육은 제도가 만들어져서 해당되는 시대에 어쩔수없이 시간이 걸린다. 교과서 프로세서 만들어지는 시간 걸린다. 이런 변혁 시기에는 제도권에서는 기대 안하는 것이좋다. 되려 많은 곳에서 정보를 보고 비판하는 능력. 자기학습하는 능력을 키워지는 능력이 더 중요한것 같다.
강의를 듣고 창업을 하고 싶다는 생각이 많이 들었다. 개인적으로 해결해야할 문제도 있고 어느 환경에서 어떻게 써야하고 데이터를 어디서 얻을수 있는 지도 일단 마음속에서 정리를 해놓은 상태인데 이 단계에서 인공지능 비즈니스를 시작하겠다면 우선적으로 어떤식으로 어떻게 준비해야할지 궁금하다.
창업이라는 것은 그냥 창업하겠다고 막 시작하면 답이 안나온다. 그래서 직장을 다니시는 분들은 직장 다니면서 당분간 하다가, 진짜 이게 되겠다는 고객반응, 이런 것들이 생기면 그때 하는것이 낫다 .중요한 것은 빌드하는것 작게부터라도. 아까 스테이빌리티 AI 같은 경우도 디스코드에서 만든것도 그렇고 런웨이ML 같은 것도 그렇고 창업하고 만든것이 아니다. 커뮤니티 활동하고 학교 다니면서 이것저것 만들어 봤는데 사람들이 좋고 쓰고 더 해야되는 상황이 되니까 더 좋게 만들고 하다보니 기술도 좋아지고 동료도 붙고 투자도 들어오고, 이렇게 창업된것이다. 창업을 한것이 아니라 창업이 된것이다. 이런 과정이 자연스럽고 성공가능성이 높다고 생각한다. 바로 그만드고 바로 시작하겠다? 젊은 시기에 젊을 때 시간도 있고 열정 해보겠다 하는 사람 해도 되는데 꼭 그것만이 답은 아니다. 뭐라도 하고 싶은 사람끼리 엮어서 뭔가 팀을 짜고 시작을 해서 해야된다. 일하다보면 누구랑 뭘 해야하는지 알아야하니까.
AI 를 통해서 인류를 질병으로 부터 도와주고 구원할 수 있다고 생각한다. 창업에 실질적인 질문일 수도 있는데, 강연하시면서 많은 기업들 보여주시고 성장과정 보여주셨는데 그 기업들 같은 경우 이름 알리고 투자 들어오고 하는데, 실질적으로 투자를 스타트업이나 창업을 한다고 했을떄 받을 수 있는 경로 궁금한다.
철학에 따라 다른데 예를 들어서 피터티엘 장학금, 대학 중퇴하고 그러면 그냥 2만불씩 막 뿌리는, 저희나 펀드는 투자심사 절차, 여러가지 제품없이 하는 경우는 없다. 다만 창업활성화를 하기 위해 우리나라 같은 경우에는 예비창업 패키지, 그런 시도해볼수 있도록하는 정부지원 프로그램 있다. 아무것도 없을떄 할 수 있는 접근 방법. 그런 것 없이 그냥 투자부터 바라면 다 실패한다고 보면 된다.
만들고 그것이 투자자가 보기에 임펙트가 있고 되겠다는 생각이 들어야 투자를 하겠다. 기관들은 이 단계는 투자 안하고 아마도 엔젤투자가 투자한다.
다 쓰고 나니까 하루가 그대로 날라갔다. 오랫만에 사람, 조직, 내용을 재밌게 들어서 즐거운 세미나였다. 교수님께서 하신 말씀중에 크게 남는 부분이 몇개가 있다.
“우리도 할 수 있었는데” 동시대에 같은 내용을 같이 연구했는데 커뮤니티도 만들어서 했는데, 우리는 열심히 공부해서 회사가서 회사일 열심히 했다는 말
인간으로써 꼭 갖춰야하는 교육이 더 중요한것 같다. 개인적으로 윤리나 어떤 것이 예쁘고 아름답고 기쁘고 감동이뭐고 이런 것들, 체육이 뭐고 몸의 어떤, 인간 그 자체, 인간으로 관련된 그런 교육이 중요하지 않을까.
네트워킹, 커뮤니티, 인맥
그리고 나의 관심사이제 이것 때문에 본 키워드는
pathways
robotics